1.Motivation
尽管有了RAG的帮助,LLM仍有可能给出与所提供知识不符的回答。因此需要构建一个数据集来检测幻觉。
2.Contributions
- 提出RAGTruth,一个大规模词级别的幻觉检测数据集,由LLM自然产生(作者认为故意触发的幻觉与自然产生的幻觉存在差异)
- 对现有幻觉检测方法进行比较
- 提出了微调LLM用于幻觉检测的基线。Llama-2-13B在RAGTruth training data上微调后比得上GPT4
- 证明了使用微调得到的幻觉检测器,能降低幻觉
3.Related Work
4.Methods
1.Hallucination Taxonomy幻觉类型
本文将幻觉类型分为:
- Evident Conflict明显冲突:与提供的文本明显相反,容易辨别,如事实错误、拼写错误、数字错误。
- Subtle Conflict轻微冲突:生成的信息与提供的文本有歧义,比如术语的替换,需要结合上下文判断。
- Evident Introduction of Baseless Information明显引入无根据知识:生成的内容不在提供的信息之内。
- Subtle Introduction of Baseless Information轻微引入无根据知识:生成内容超出了提供的信息,比如主观的假设或推断。
2.Response Generation回答生成
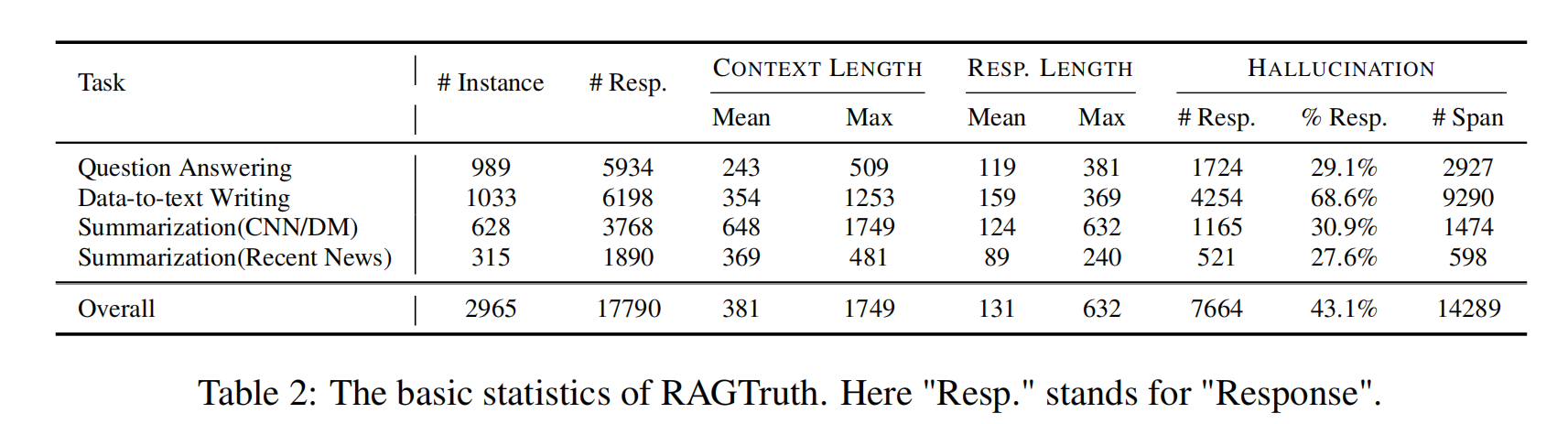
选择三个任务: Question Answering,Data-to-text Writing, and News Summarization.(问题回答、数据到文本的写作、新闻摘要),生成回答并人工标注幻觉部分。
- Question Answering:从MS MARCO选择与生活相关的QA,每个问题保留三段提取内容,然后使用LLM根据内容回答问题。
- Data-to-text Writing:从Yelp数据集选择有关商家的结构化信息和用户的评论,用LLM生成对商家的描述。如果数据出现空值而大模型将其解释为“假”,认为这是出现了幻觉。
- News Summarization:数据来自CNN/Daily Mail dataset+某新闻平台的新闻,使用LLM对每篇内容生成摘要。
使用的LLM:GPT-3.5-turbo-0613、GPT-4-0613、Mistral-7b-Instruct、Llama-2-7B-chat、 Llama-2-13B-chat、 Llama-2-70B-chat
每个任务都用6个模型跑一遍,得到6个回答。
5.Result
各项任务中幻觉类型的比例:
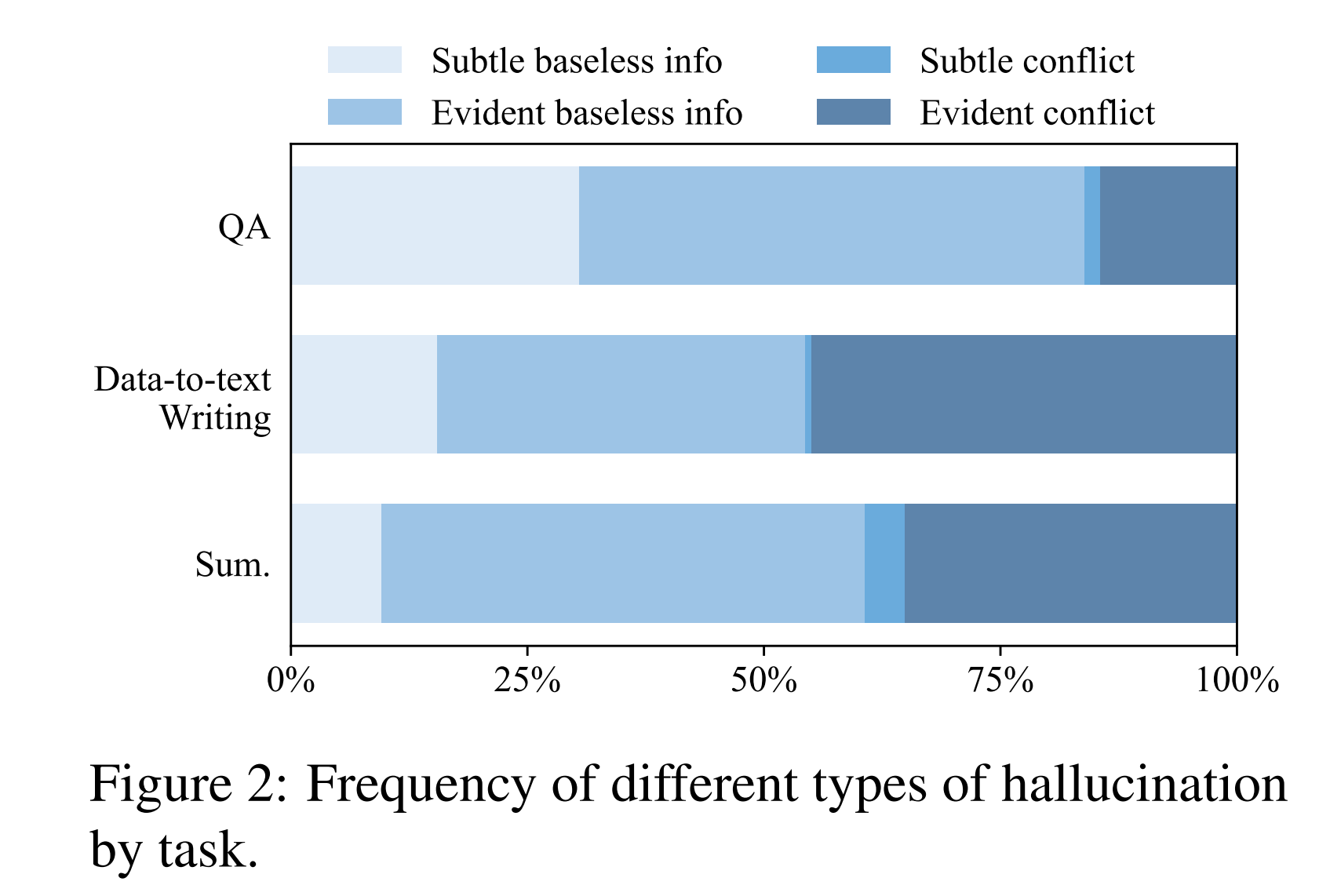
如图2所示,在上下文中无根据的信息生成显著多于与上下文冲突的信息生成,尤其是在问答任务中。在两大类无根据信息和冲突信息中,更严重的幻觉,即明显的无根据信息和明显的冲突信息,占据了相当大的比例。这一观察结果说明即使有RAG,还是存在严重幻觉。
数据转文本的任务幻觉率最高,可能与JSON格式有关。另外,较新的新闻的幻觉率不比过时新闻高,可能是由于较新的新闻的文本长度较短。
各模型出现幻觉的比例:
(span、density什么意思)
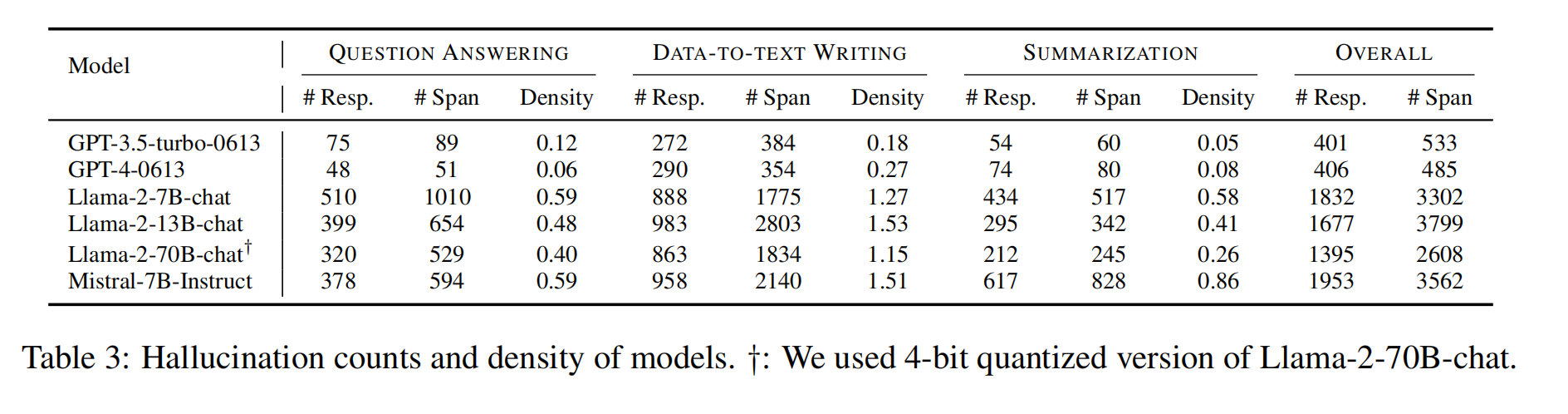
表3显示,在我们收集的数据中,OpenAI的两个模型表现出显著较低的幻觉率。具体来说,GPT-4-0613的幻觉频率最低。为了更清晰地比较不同模型的幻觉率,我们计算了每个模型在三个任务中的幻觉密度。幻觉密度定义为每一百个单词响应中平均出现的幻觉跨度数。在Llama2系列中,除了数据总文本写作任务外,模型规模与幻觉密度之间存在明显的负相关关系。尽管Mistral-7B-Instruct模型在各种基准和排行榜上的表现强劲(Zheng等人,2023),但它生成的包含幻觉的回答数量最多。
幻觉与文本长度的关系:
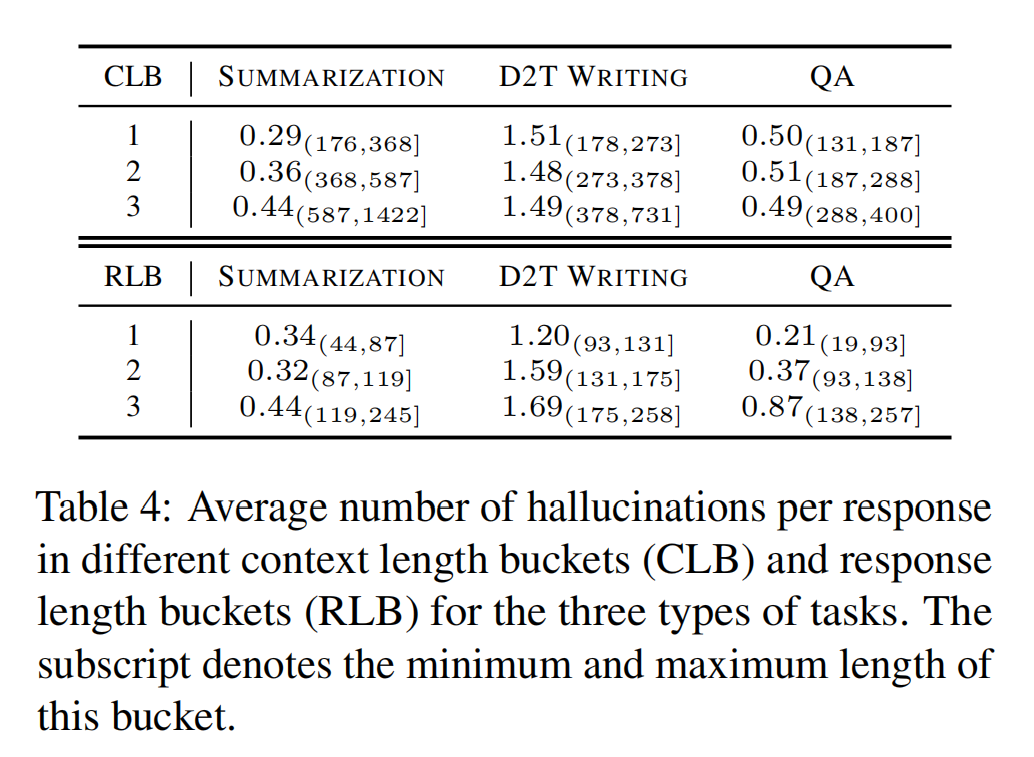
对于上下文长度(CLB),只有新闻摘要呈现出上下文越长,越容易幻觉的特点。
对于回答长度(RLB),都有回答越长,越容易幻觉的特点。
幻觉与位置的关系:
在问答和新闻摘要任务中,幻觉更倾向于出现在回答的末尾。数据到文本写作任务在前半部分较易出现幻觉。