EMNLP2024
0.主要贡献
- 提出了Lumberchunker文本分割方法
- 提出了GuntenQA数据集
- 验证了Lumberchunker在下游RAG任务上的效果
1.LumberChunker
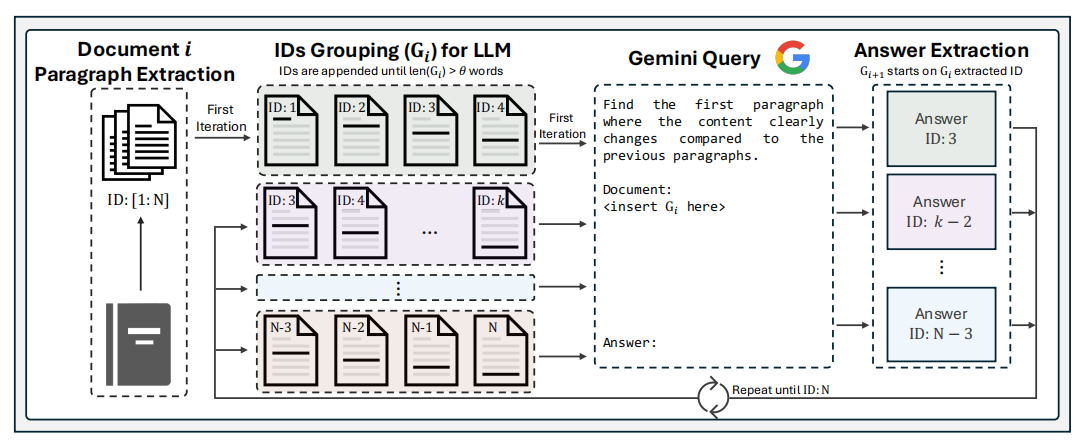
使用LLM动态的将文档分割为语义独立的片段。每个片段的长短是不固定的,确保每个片段的语义完整性、独立性。也就是说分割后,每一段包含的语义是完整的,同时与其它段有区别。由LLM来确定合适的分割点,这一决策过程考虑到文本的结构和语义,从而能够创建出大小最优且上下文连贯的片段。
1.先按照paragraph分割目标文档,然后把paragraph顺序连接,直到累计的token数超过一个阈值 $\theta$,形成 $ G_i$。该阈值如何设置后文会说。$\theta$ 应该足够大,防止把具有相关性的段落分开;同时 $\theta$ 也要足够小,防止过多内容影响LLM进行推理。
2.让LLM寻找 $G_i$ 中“语义断层”的地方,作为分割点。分割点之前即形成一个chunk。剩下的内容继续与paragraph顺序拼接、超过阈值停止、LLM分割……分割整体是串行进行的。
2.GutenQA
数据来源于Project Gutenberg电子图书馆。
1.100本英文书籍,手动提取HTML内容(附录里和NarrativeQA进行了对比,手动提取没有编码错误等问题)
2.使用ChatGPT3.5为每本书生成问题、答案和包含答案的原文片段,人工为每本书筛选30个高质量问题。
问题需要基于给定片段中的具体信息,且不能用书中的其它地方的信息来回答。问题大多以‘what,’ ‘when,’ ‘where’ 开头, ‘why’ and ‘how’较少。
3.原文片段需要简短,以确保任何分块方法都不会把它切开。评估方法是在检索到的文本中精确匹配字符串。
3.Experiments
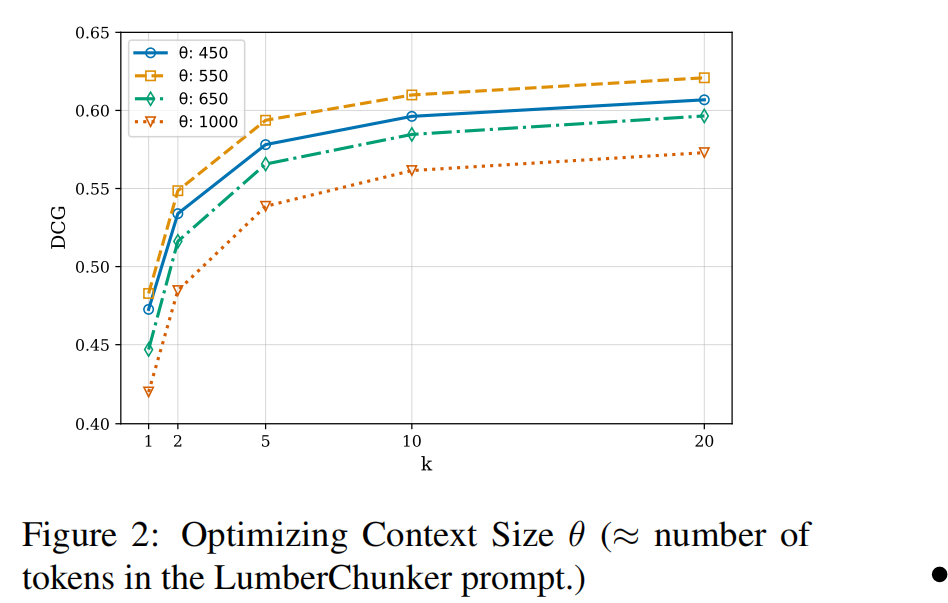
3.1 propmt的阈值怎么选择
这个阈值就是paragraph顺序连接的阈值 $\theta$ 。由于是LLM寻找分割点,token过长会影响模型的推理能力。
在不同阈值下使用DCG评估效果。DCG表明了是否检索到,检索结果是否靠前。
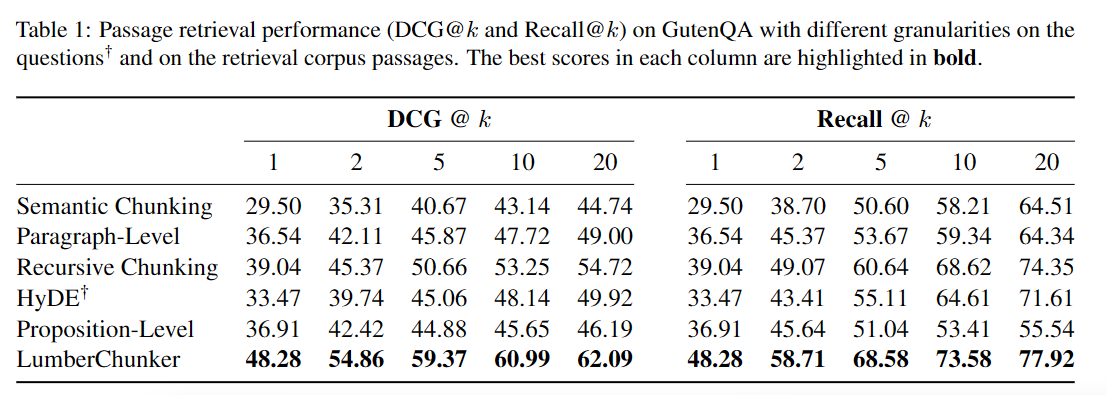
3.2 Lumberchunk是否增强了检索效果?
与其它分块基准进行对比。评估指标为DCG@K、RECALL@K。

此外,注意到semantic chunk和paragraph level的指标并没有随K有效增加,表明其在大规模文档检索方面的局限性。
proposition level的引用在哪???
附录F展示了各分割方法的统计结果:
Lumberchunk切分后的块平均长度为334,比预设的550阈值低了40%,这说明LLM有效的对文本进行了切分,而不是持续选择靠近末尾的ID。说明未出现Lost in the Middle现象。
在论文《Lost in the Middle: How Language Models Use Long Contexts》中,作者发现,当针对长文本的不同位置信息设计专门问题,测试大语言模型对不同位置信息的记忆能力时,模型的性能呈现一种 “U 型” 表现,即对于前段与后段的信息有着较强的关注与记忆能力,能较好地解决问题,而对于中段信息的利用则有所逊色。
这种现象的产生可能是由于训练数据中的无意偏差。LLM 的预训练侧重于根据最近的一些 token 预测下一个 token,而在微调过程中,真正的指令又往往位于上下文开始的位置,这在不知不觉中引入了一种立场偏见,让 LLM 认为重要信息总是位于上下文的开头和结尾。
由于文章中对话较多,所以paragraph chunk token较少;recursive接近langchain预设的450token;proposition level与先前研究中的token接近,11token左右。semantic chunk由于对话较多,段落较短,可能语义比较跳跃,导致其avg token偏小。
3.3 Lumber是否增强了下游的答案生成效果?
开发了一个RAGpipeline进行测试。测试数据来自4部自传体作品,包括280个问题。与其它RAG进行对比,还与纯LLM对比。
3.4 Lumberchunker与人类手动分块的效果有多相似?这种相似性又与准确性有什么关系?
与recursive比较,用Rough-L评价,确实更像人分的块。这可能是导致RAG效果好的原因。
4.Limitations
- 串行使用LLM,慢——改为并行
- 只使用了GutenQA一个数据集,叙事型的,不具有普遍性——多几个数据集/寻找通用的prompt