1.Motivation
现有的神经检索(neural retrieval)的方法主要集中在短文本排序,在长篇文章中做检索效果并不好(由于自注意力机制token数量的限制;或者返回的文档过长,不便于用户使用)。另外,作者发现在先进检索器的检索错误中,半数错误与缺少上下文有关。
比如:在A剧场中演出过的演员有哪些?如果只检索关键字“A剧场”,可能找不到答案,需要结合上下文找到“……在这里演出过……”的内容才是真正答案。
因此,作者针对上下文强关联的任务建立了一个数据集,使用两类方法(hybrid retrieval with BM25、 contextualized passage representations)进行实验,并详细解释了实验结果。
2.Related work
- Document Question Answering(DocQA):要求模型回答关于输入文档的问题,通常假设文档在提问前就已给出。本文提出的(Document-Awarepassage Retrieval, DAPR)与DocQA类似,区别在于DAPR希望用户提问时不知道目标文档,由模型来寻找目标文档。
- Long-document retrieval(长文档检索):对于长文档检索有一些简单的方法:将文档中段落相关性的最大值作为文档的相关性(MaxP);仅编码文档中的第一个段落(FirstP)……与DAPR相比,所有这些先前的工作都没有研究如何在考虑文档上下文的情况下检索段落。
- Hybrid retrieval(混合检索):对于一个查询使用多个检索系统(常常是BM25+神经检索)
- rank fusion(排名融合)——通过凸组合、互逆排名等方法将不同检索系统的个体排名合并为一个。
- hierarchical retrieval(层次检索)——首先检索文档,然后从这些文档中检索段落。只适用于段落本身足以对查询做出响应的情况。
- 本文探讨了段落排名和文档排名结合的有效性。
- Relation to pre-training tasks(和预训练任务的关系):有的研究在预训练中加入上下文。但推理时仍然只关注独立的段落。
- 补充:
- NQ:谷歌的一个问答数据集
- NDCG:评价检索序列的相关性和位置
- 共指信息:描述文本中不同表达式指向同一实体或概念的语言现象,如*“玛丽打开了门,她随后拿起包。”* → “她”与“玛丽”共指同一人。
- 共指消解(Coreference Resolution):自动识别文本中所有指向同一实体的表达式并分组。
3.Method
DAPR任务要求系统提取+排序。给出段落集合$C$,文档集合$D$,对于查询集合$q \in Q$,检索系统$s$应该提取出最好的$K$个段落集合$R$。
3.1NQ-Hard
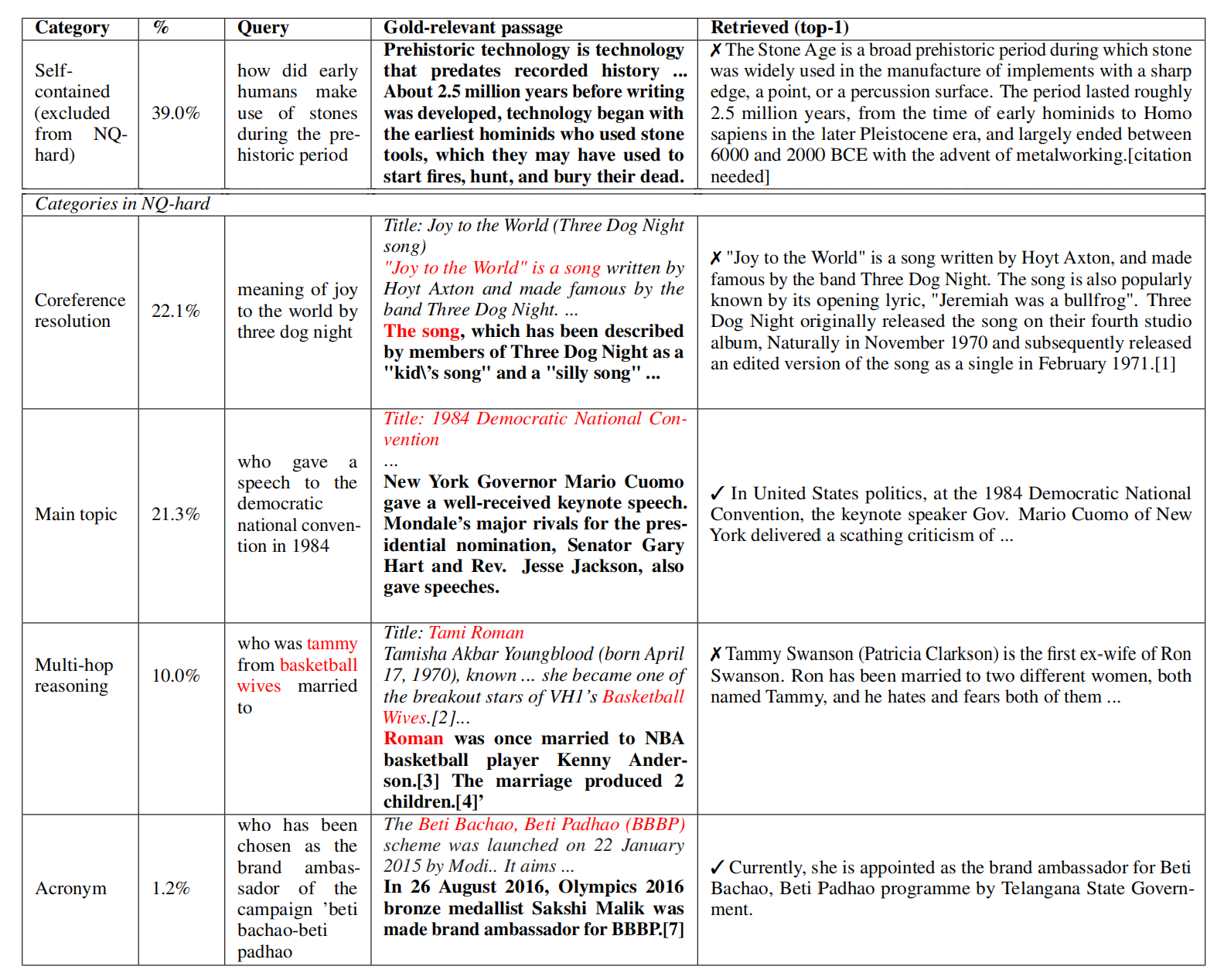
对SOTA的检索器(DRAGON+,SPLADEv2, and ColBERTv2)使用NQ数据集,发现一半的错误来自于不了解上下文。将这些数据命名为NQ-hard,并分为4类:
- 共指消解(CR):关键的共指信息需要通过特定文档上下文来解析;
- 主要主题(MT):只有了解文档的背景主题(通常是标题),才能回答查询;
- 多跳推理(MHR):连接查询和查询相关段落中的实体的推理路径包括文档上下文中的其他节点;
- 缩写(AC):在相关段落(或查询)中出现一个缩写,该缩写对应于查询(或相关段落)中的全称,文档上下文解释了这种映射;
3.2Datasets
MS MARCO、Natural Questions、MIRACL、Genomics 和 ConditionalQA(具体处理方式见附录A)有语料库的直接用,没有的把黄金段落文本收集起来当语料库。(也是很神奇)
3.3Evaluation
使用nDCG@10和recall@100做指标。
将binary/3-scale转换为0-1/0-1-2,然后使用pytrec_eval计算指标。
考虑到现实世界中的检索系统多用于零样本、跨领域的情景,本文进行了一项测试:在MS MARCO训练集训练,然后在MS MARCO测试集测试,作为域内评估;在其它四个数据集上测试,作为域外评估。
4.Experiments
4.1基础检索器
- BM25(使用PySerini的默认配置)
- neural retrievers:DRAGON+、SPLADEv2、ColBERTv2(在MS MARCO上训练)
4.2两种将上下文引入神经检索器的方法
4.2.1加入BM25的混合检索
(1)Rank fusion融合检索
由于神经网络适合于检测512tokens内的段落,而BM25无长度限制,所以使用BM25检索整个文档,而使用神经检索器检索段落。
相关性分数为:
$$s_{convex}(q,p,d)=\alpha\hat s_{BM25}(q,p) + (1-\alpha)\hat s_{nueral}(q,d)$$(公式有误)
$\hat s_{BM25},\hat s_{nueral}$的分数都是归一化的。归一化公式为:
$$\hat{s}(q, c) = \frac{s(q, c) - m_q}{M_q - m_q}$$
- $s(q, c)$:检索器对查询(q)和候选文本(c)(段落或文档)的原始分数。
- $m_q和M_q$:当前查询(q)的Top候选结果中分数的最小值和最大值。
- 若候选文本(c)在某一检索器的结果中缺失(未进入Top列表),则其分数视为0。
分数计算示例:
输入数据:
- 5篇文章,每篇2个段落:
- 文章D1:段落P1, P2
- 文章D2:段落P3, P4
- 文章D3:段落P5, P6
- 文章D4:段落P7, P8
- 文章D5:段落P9, P10
- 文档级检索结果 (topk=2):
- 得分:D1=0.8, D2=0.6(其他文档得分低于这两个)
- 段落级检索结果 (topk=2):
- 得分:P3=0.9, P5=0.7(其他段落得分低于这两个)
- 段落到文档映射:
pid2did = { 'P1':'D1', 'P2':'D1', 'P3':'D2', 'P4':'D2', 'P5':'D3', 'P6':'D3', 'P7':'D4', 'P8':'D4', 'P9':'D5', 'P10':'D5' }
- 段落权重:假设
passage_weight=0.4(文档权重自动为0.6)计算过程:
- 构建得分映射:
did2score = {'D1':0.8, 'D2':0.6} # 文档级top2 pid2score = {'P3':0.9, 'P5':0.7} # 段落级top2
- 传播文档得分到段落:
doc_pid2score = { 'P3': did2score['D2'], # P3属于D2 → 0.6 'P5': did2score['D3'] # 但D3不在did2score中(文档级只返回了D1,D2) }实际结果只有
{'P3':0.6},因为D3不在文档级top2中
- M2C2融合(假设是线性加权):
- 对P3:
- 文档得分:0.6
- 段落得分:0.9
- 融合得分 = 0.6*0.6 + 0.9*0.4 = 0.36 + 0.36 = 0.72
- 对P5:
- 文档得分:无 → 可能视为0或忽略
- 段落得分:0.7
- 如果忽略文档部分:0.7*0.4 = 0.28
- 最终融合结果:
fused = {'P3':0.72, 'P5':0.28}
(2)Hierarchical retrieval层次检索
第一步先BM25检索文档,第二步神经检索搜索段落,并在第二步应用带有分数归一化的排名融合。
4.2.2上下文化的段落表示
(1)**Prepending titles:**将文章标题放在每个段落的开头,并用特殊标记分割。可能会出现文档无标题或标题无意义。
(2)**Prepending document keyphrases:**使用TopicRank算法(不知道在RAG中,和大模型抽取关键词相比如何)提取出文档的十个关键词,放在每个段落之前。
(3)**Coreference resolution(共指消解):**使用SpanBERT-large model,采用c2f-coref方法,在OntoNotes上微调。然后用模型对文档生成代词-先行词映射。将代词与文档中最早出现的先行词关联。将先行词放入括号,附在对应的代词后面。比如 “曾在该场地(xx剧场)”
5.result

5.1混合检索
rank fusion略好于hierarchical,但都不能解决NQ-Hard问题。说明这两种方法都只能提高自包含问题的表现。
统计了检索性能随融合权重变化的曲线。发现NQ上的最佳融合权重不能直接转移到NQ-hard上。
5.2上下文化段落表示
添加标题和关键词都相当于添加摘要,提升效果相当;共指消解表现最差。
在NQ-Hard问题(需要连接上下文的问题)的表现显著优于混合检索。
6.Disscution
1.为什么混合检索在Hard问题上表现不佳
通过MaxP方法将查询-段落的指标转为查询-文档的指标,作者发现rank fusion和hierarchical检索出的文档大都正确,说明它能找到相关文档,但段落排序表现非常差,说明这两种方法不能够有效的对段落进行排序。
另外,作者提到fusion weight 在 NQ-Hard和普通问题中的变化趋势不同。所以使用混合检索不能同时在两类问题上达到最佳表现。

2.为什么在Genomics上上下文表示结果变差
计算了加/不加标题的文档与query的Jaccard相似度,只有Genomics加标题后值减小。说明添加标题引入了更多不相关的内容,帮倒忙。
Jaccard 相似度公式:$\text{Jaccard}(A, B) = \frac{|A \cap B|}{|A \cup B|}$
- $A $ 和$B $:两个文本的词集合(或更广义的集合)。
- $|A \cap B|$: A 和 B 中**共同词(交集)**的数量。
- $|A \cup B| $: A 和 B 中**所有唯一词(并集)**的数量。
取值范围 $[0, 1]$(0 表示无重叠,1 表示完全一致)。
优点:
- 简单直观,适用于短文本或集合型数据
- 不依赖词序或语义(仅统计词重叠)
缺点:
- 忽略语义:同义词(如“电脑”和“计算机”)会被视为不同词。
- 敏感于词频:未考虑词的重要性(如TF-IDF),可以给词添加权重作为改进。
- 长文本效果差:并集会急剧增大,导致相似度被低估。
3.错误分析
在两种融合检索、三种上下文化的方法下,多跳推理MHR最难解决,缩写最易解决。使用共指消解不如直接添加标题,因为标题往往含有核心词,而共指消解多次在段落中插入内容,反而干扰了匹配。
该文章中了ACL2024。在连接上下文方面使用的方法比较淳朴。主要是定义了NQ-Hard数据集,并在5个数据集、原始方法+2个混合检索+3个上下文检索上做了一系列实验,并很好的解释了现象。
复现
把README里的loaddata和evaluation的代码复制到dapr根目录load.py和eval.py下
pip install -r requirements.txt
有setup.py,在根目录下python setup.py build python setup.py install 解决module’dapr’ not found
sudo apt-get update
ConditionalQA数据集
ConditionalQA给定提问者特定情况下的情景,回答与英国政策相关的问题。每个问答实例都标注了来自英国政府政策网页的证据。我们将原始数据集中的所有此类网页作为语料库。每个网页最初被解析为HTML标签,我们将其视为段落,移除HTML标签,仅保留纯自然语言。对于每个问答实例,我们将情景和问题连接起来形成一个查询,并将相应的证据视为黄金相关段落。
预处理后的train(原版的数据没有文章和句子的id,这是处理后的数据)
{
"query": {
"id": "train-0", //train条目编号
"text": "My father, who was a widower and the owner of several large properties in Wales, died recently and apparently intestate. My paternal uncle is applying for probate, but I believe that I have a stronger claim. Do I have a greater right to probate in respect of my late father's estate?"
},
"judged_chunks": [ //判断点,一个问题可能有多个黄金段落
{
"chunk": {
"id": "74-24",
"text": "<p>You can apply to become the estate’s administrator if you are 18 or over and you are the most ‘entitled’ inheritor of the deceased’s estate. This is usually the deceased’s closest living relative.</p>"
},
"judgement": 1, //都为1
"belonging_doc": { //每个chunk都把"belonging_doc"详细写了一遍,导致文件很大
"id": "74",
"title": "Applying for probate",
"chunks": [
{
"id": "74-0",
"text": "Overview"
},
...
{
"id": "74-138",
"text": "Once you have probate you can start dealing with the estate."
}
],
"candidate_chunk_ids": [
"74-5",
...
"74-51"
]
}
}
...
]
}
预处理后的test
{
"query": {
"id": "dev-0", //问题编号
"text": "My brother and his wife are in prison for carrying out a large fraud scheme. Their 7 and 8 year old children have been living with me for the last 4 years. I want to become their Special Guardian to look after them permanently How long will it be before I hear back from the court?"
}, //具体问题
"judged_chunks": [
{
"chunk": {
"id": "86-41", //黄金匹配段落
"text": "<p>Within 10 days of receiving your application the court will send you a case number and a date for a meeting to set out:</p>"
},
"judgement": 1, //不知道什么意思,取值应该全部为1
"belonging_doc": {
"id": "86",
"title": "Become a special guardian",
"chunks": [ //chunks是该问题相关的法条界面的文本分割后的结果。一段话设置为一个chunk
{
"id": "86-0",
"text": "What is a special guardian"
},
{
"id": "86-1",
"text": "You can apply to be a child’s special guardian when they cannot live with their birth parents and adoption is not right for them."
},
...
{
"id": "86-62",
"text": "You might be able to get a special guardian allowance from the children’s services department of your local council."
}
],
"candidate_chunk_ids": [ //把chunkid重新排了一遍,不知道按照什么要求排的
"86-6",
"86-52",
...
"86-57",
"86-14",
"86-2",
"86-16"
]
}
}
]
}
prepending_titles/bm25/CQA
query是一个字典,包括id,content。DAPR把每句话所属文章的标题也作为一个title字段加进去了。比如{"id": "0-0", "title": "Child Tax Credit", "contents": "Overview"}
这里的bm25使用了pyserini,是用java实现的。然后把corpus字典传给java接口去index。应该是把title和content并为一个字符串。而且是以一句话而不是一篇文章进行的index。
那对于NQ这种没有文章标题,只有零散段落的怎么prepending_titles呢?