参考:https://zhuanlan.zhihu.com/p/403495863
1.介绍
BERT(Bidirectional Encoder Representation from Transformers)是2018年10月由Google AI研究院提出的一种预训练模型,该模型在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。
BERT的网络架构使用的是《Attention is all you need》中提出的多层Transformer结构。其最大的特点是抛弃了传统的RNN和CNN,通过Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。Transformer的结构在NLP领域中已经得到了广泛应用。
2.模型结构
下图展示的是BERT的总体结构图,多个Transformer Encoder一层一层地堆叠起来,就组装成了BERT了,在论文中,作者分别用12层和24层Transformer Encoder组装了两套BERT模型,两套模型的参数总数分别为110M和340M。
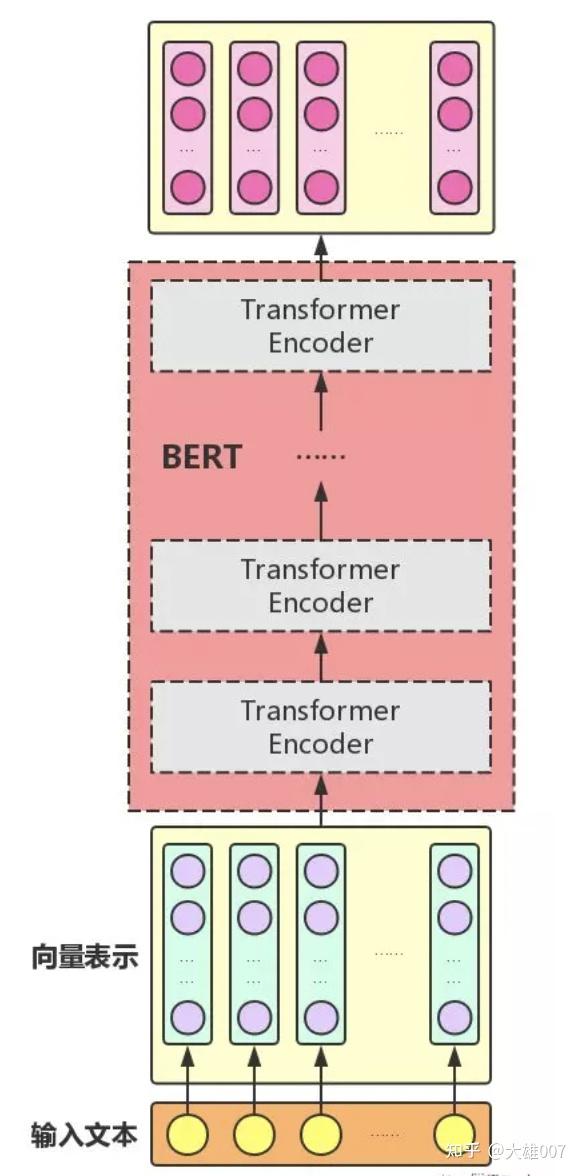
BERT是用了Transformer的encoder侧的网络,encoder中的Self-attention机制在编码一个token的时候同时利用了其上下文的token,其中‘同时利用上下文’即为双向的体现,而并非像Bi-LSTM那样把句子倒序输入一遍。在BERT之前是GPT,GPT使用的是Transformer的decoder侧的网络,GPT是一个单向语言模型的预训练过程,更适用于文本生成,通过前文去预测当前的字。
2.1Embedding
Embedding由三种Embedding求和而成:
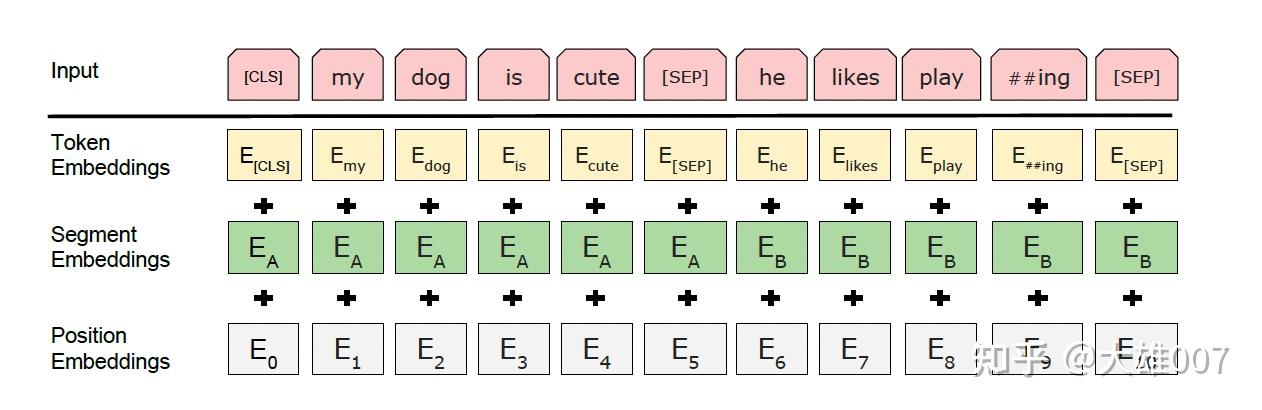
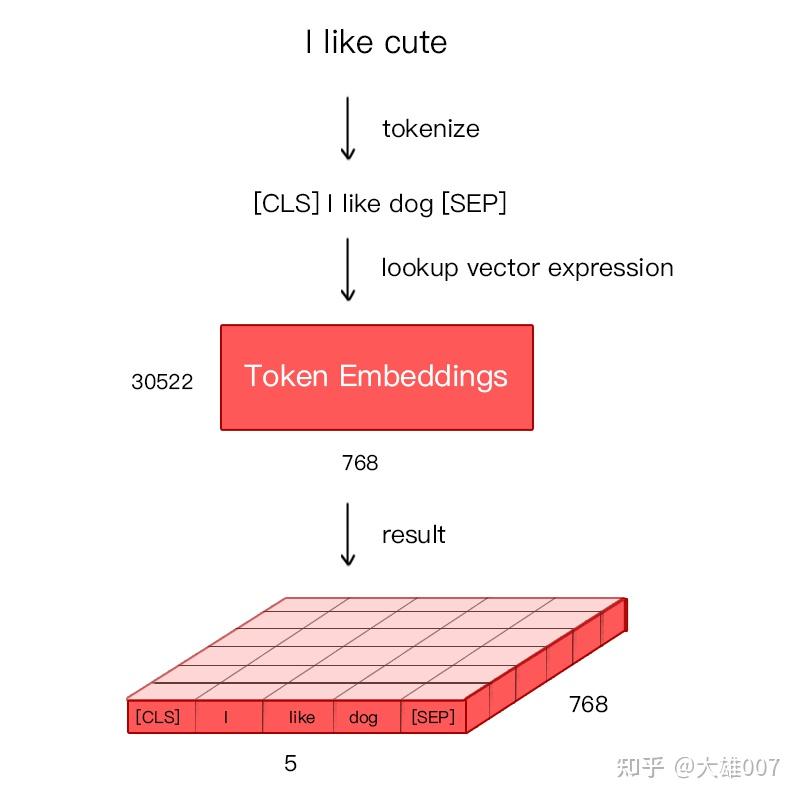
token embedding
将输入的文本进行Word Piece分词,如playing切割成play,##ing,使用Word Piece是为了解决未登录词。tokenization后,在开头插入[CLS],在每句话的末尾插入[SEP]。[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
Bert 在处理英文文本时只需要 30522 个词,Token Embeddings 层会将每个词转换成 768 维向量,如下图的例子中, 5 个Token 会被转换成一个 (5, 768) 的矩阵或 (1, 5, 768) 的张量。
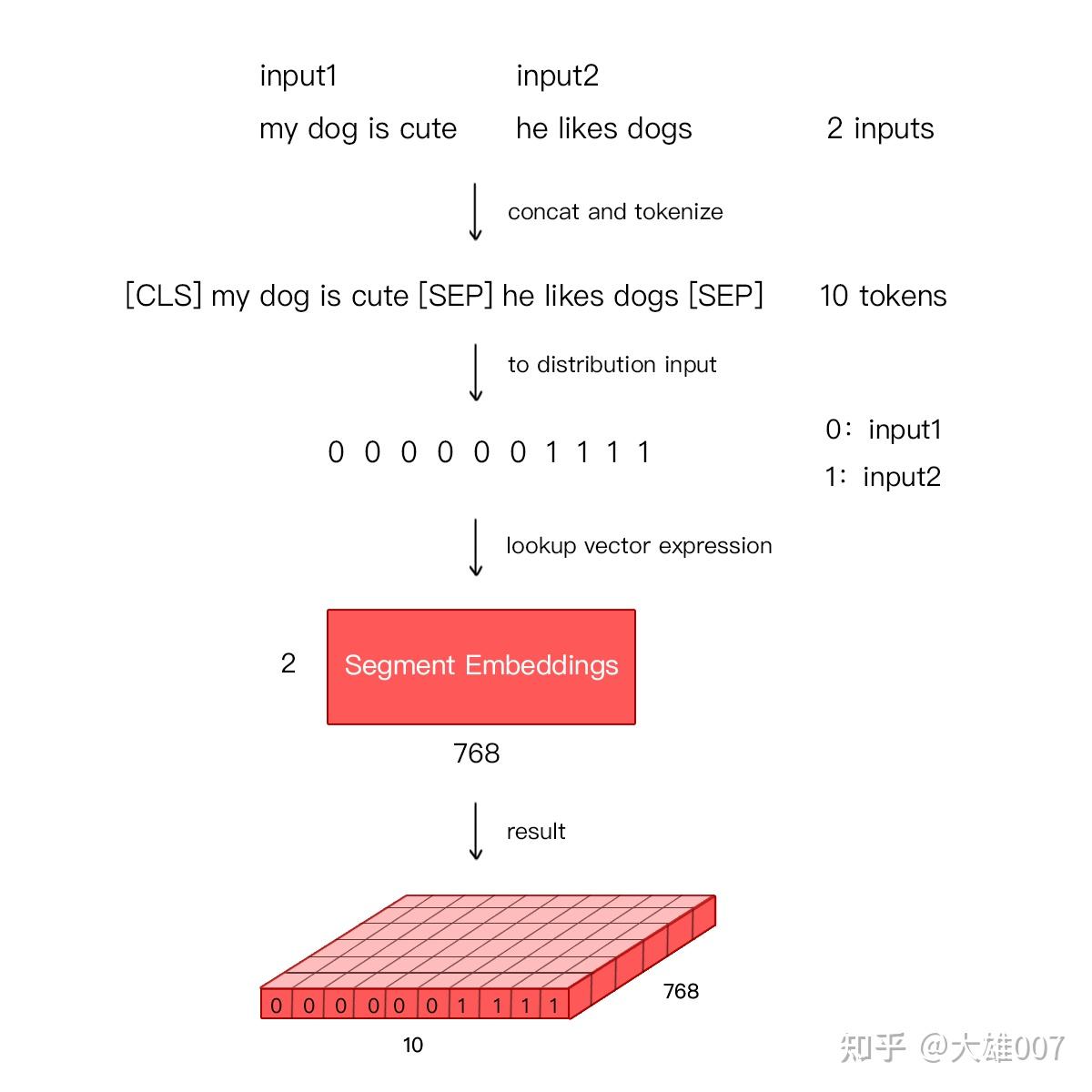
segment embedding
用来区分两种句子。bert在训练时包括两种任务,其一是MLM(masked language model,掩码语言模型),就是遮住某个词让模型去预测;其二是NSP(next sentence prediction,下一句预测),输入两个句子,让模型判断是否相关。这时候就需要segment embedding对两个句子做区别。
进行问答等需要预测下一句的任务时,segment embedding层把0赋值给第一个句子的各token,把1赋值给第二个句子的各token。在文本分类任务时,segment embedding全部为0。
position embedding
和transformer的实现不同,不是固定的三角函数,而是可学习的参数。
Transformer 中通过植入关于 Token 的相对位置或者绝对位置信息来表示序列的顺序信息。作者测试用学习的方法来得到 Position Embeddings,最终发现固定位置和相对位置效果差不多,所以最后用的是固定位置的,而正弦可以处理更长的 Sequence,且可以用前面位置的值线性表示后面的位置。
在BERT中,Position Embeddings层被引入以解决Transformer模型无法编码输入序列顺序性的问题。在自然语言处理任务中,词的顺序往往很重要。例如,“I think, therefore I am”中,“I”的顺序不同,表达的含义也不同。Position Embeddings层通过添加位置信息,让BERT能够理解词的位置关系,从而更好地处理文本数据。在BERT中,位置信息被编码成一系列向量,这些向量被加到Token Embeddings层的输出上,形成最终的词向量表示。通过这种方式,BERT能够理解词的位置关系,从而更好地处理文本数据。
BERT 中处理的最长序列是 512 个 Token,长度超过 512 会被截取,BERT 在各个位置上学习一个向量来表示序列顺序的信息编码进来,这意味着 Position Embeddings 实际上是一个 (512, 768) 的 lookup 表,表第一行是代表第一个序列的每个位置,第二行代表序列第二个位置。
最后,BERT 模型将 Token Embeddings (1, n, 768) + Segment Embeddings(1, n, 768) + Position Embeddings(1, n, 768) 求和的方式得到一个 Embedding(1, n, 768) 作为模型的输入。
(不明白怎么赋值的)
[CLS]的作用
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。 具体来说,self-attention是用文本中的其它词来增强目标词的语义表示,但是目标词本身的语义还是会占主要部分的,因此,经过BERT的12层(BERT-base为例),每次词的embedding融合了所有词的信息,可以去更好的表示自己的语义。而[CLS]位本身没有语义,经过12层的信息传递后编码了全局语义,相比其他正常词,可以更好的表征句子语义。
分类的时候把cls位置的向量取出来即可。
2.2Encoder
BERT使用了Transformer的encoder侧的网络。
在Transformer中,模型的输入会被转换成512维的向量,然后分为8个head,每个head的维度是64维,但是BERT的维度是768维度,然后分成12个head,每个head的维度是64维,这是一个微小的差别。Transformer中position Embedding是用的三角函数,BERT中也有一个Postion Embedding是随机初始化,然后从数据中学出来的。
BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。
3.BERT训练
BERT的训练包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练;fine-tune阶段BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
3.1 BERT预训练
BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP。
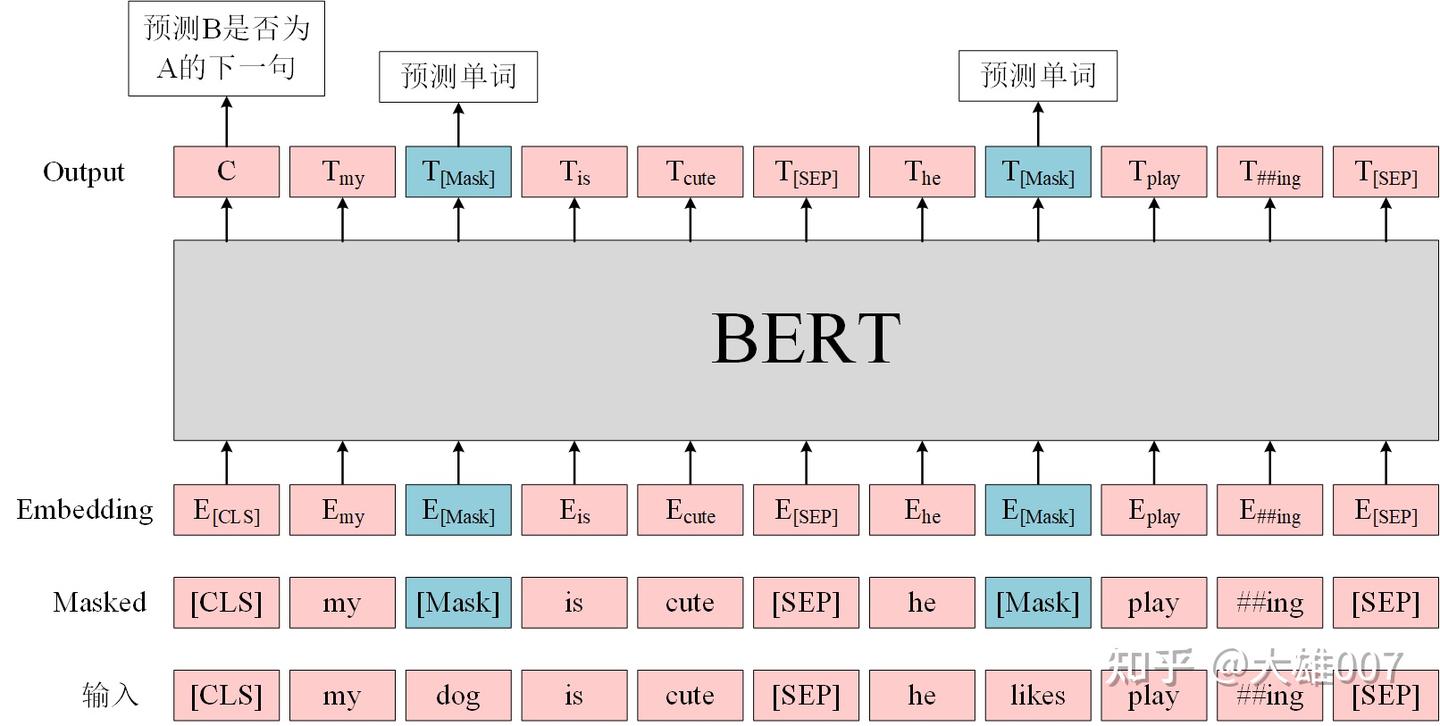
MLM
MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]"。
10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。
10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
这么做的原因是如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’cute‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。 另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
优点
1)被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
2)被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点
- 针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
NSP
Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中。
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 我 最 擅长 的 [Mask] 是 亚索 [SEP]
类别 = IsNext
输入 = [CLS] 我 喜欢 玩 [Mask] 联盟 [SEP] 今天 天气 很 [Mask] [SEP]
类别 = NotNext
注意,在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于BERT以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
BERT预训练模型最多只能输入512个词,这是因为在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的。在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。
4.BERT的优缺点
优点
- BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。
- 相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。
缺点
- 模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- BERT的NSP任务效果不明显,MLM存在和下游任务mismathch的情况。
- BERT对生成式任务和长序列建模支持不好。