简介:检索相关算法的学习
1.TF-IDF
1.1原理
TF:term frequency(词频)
IDF:inverse document frequency(逆文档频率)
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率高(TF高),并且在其他文章中很少出现(IDF高),则认为此词或者短语具有很好的类别区分能力,适合用来分类。
$TF=\frac{某个词在文章中出现的次数}{文章的总词数}$
考虑到文章长短不同,除以总词数进行标准化
$IDF=log(\frac{语料库的文章总数}{包含该词的文章数量+1})$
加1防止不存在包含该词的文档时分母为0
$TF-IDF=TF \times IDF$
优点:
- 简单快速、易理解
缺点:
- 没考虑词语的语义
- 仅用词频考虑词语的重要性不够全面。按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
- 没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
1.2自己实现
import math
# 计算每句话的词频
def counter(word_list):
wordcount = []
for doc in word_list:
count = {}
for word in doc:
count[word] = count.get(word, 0) + 1
wordcount.append(count)
return wordcount
# 计算tf=某个词在文章中出现的总次数/文章的总词数
def tf(word, word_list):
return word_list.get(word) / sum(word_list.values())
# 统计含有该单词的句子数
def count_sentence(word, wordcount):
return sum(1 for i in wordcount if i.get(word))
# 计算idf=log(语料库中的文档总数/(包含该词的文档数+1))
def idf(word, wordcount):
return math.log(len(wordcount) + 1 / count_sentence(word, wordcount) + 1) + 1
# tf-idf=tf*idf
def tfidf(word, word_list, wordcount):
return tf(word, word_list) * idf(word, wordcount)
if __name__ == "__main__":
docs = [
"what is the weather like today",
"what is for dinner tonight",
"this is a question worth pondering",
"it is a beautiful day today"
]
word_list = [] # 记录每个文档分词后的结果
for doc in docs:
word_list.append(doc.split(" "))
# 使用停用词
# stopwords = ["is", "the"]
# for i in docs:
# all_words = i.split()
# new_words = []
# for j in all_words:
# if j not in stopwords:
# new_words.append(j)
# word_list.append(new_words)
wordcount = counter(word_list) # 统计每个文档词的次数
for cnt, doc in enumerate(wordcount):
print("doc{}".format(cnt))
for word, _ in doc.items():
print("word:{} --- TF-IDF:{}".format(word, tfidf(word, doc, wordcount)))
1.3使用sklearn库
from sklearn.feature_extraction.text import TfidfVectorizer
if __name__ == "__main__":
docs = [
"what is the weather like today",
"what is for dinner tonight",
"this is a question worth pondering",
"it is a beautiful day today"
]
tfidf_vec = TfidfVectorizer()
# 利用fit_transform得到TFIDF矩阵
tfidf_matrix = tfidf_vec.fit_transform(docs)
# 利用get_feature_names_out得到不重复的单词
print(tfidf_vec.get_feature_names_out())
# 利用vocabulary_得到各单次的编号
print(tfidf_vec.vocabulary_)
# 输出TFIDF矩阵,即每个文档中每个词的tfidf值
print(tfidf_matrix)
2.BM25
2.1原理
BM25是一种基于概率检索框架的排序函数,用于计算查询(Query)与文档(Document)的相关性得分。
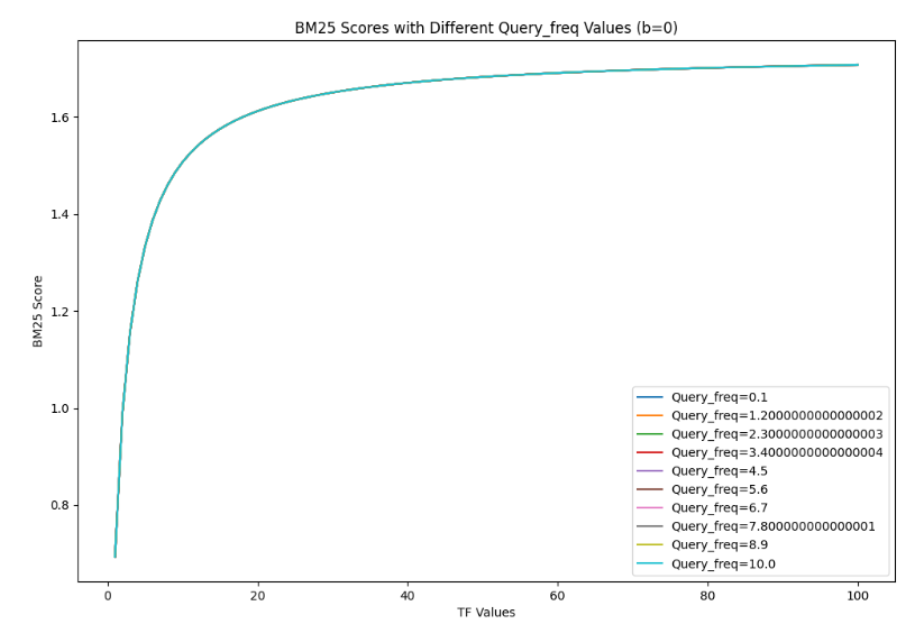
对于TF-IDF算法,如果文档长,词语多,TF值就会很大。BM25通过b参数对文档长度进行打压,随着TF的增加,BM25score趋于稳定,如下图所示。
符号说明:
- $ Q $: 查询,由一组词项组成 $ Q = (q_1, q_2, ..., q_n) $
- $ D $: 文档
- $ f_i $: 词项 $ q_i $ 在文档 $ D $ 中的出现频率(词频,TF)
- $ dl $: 文档长度(文档中的词项总数)
- $ avgdl $: 语料库中所有文档的平均长度
- $ N $: 语料库中文档总数
- $ n_i $: 包含词项 $ q_i $ 的文档数量
- $ k $: 词频调节参数(通常取1.2~2.0)
- $ b $: 文档长度调节参数(通常取0.75)
参数 典型值 作用 $ k $ 1.2~2.0 控制词频饱和度,值越大饱和度变化越慢 $ b $ 0.75 控制文档长度归一化程度,0=不归一化,1=完全归一化
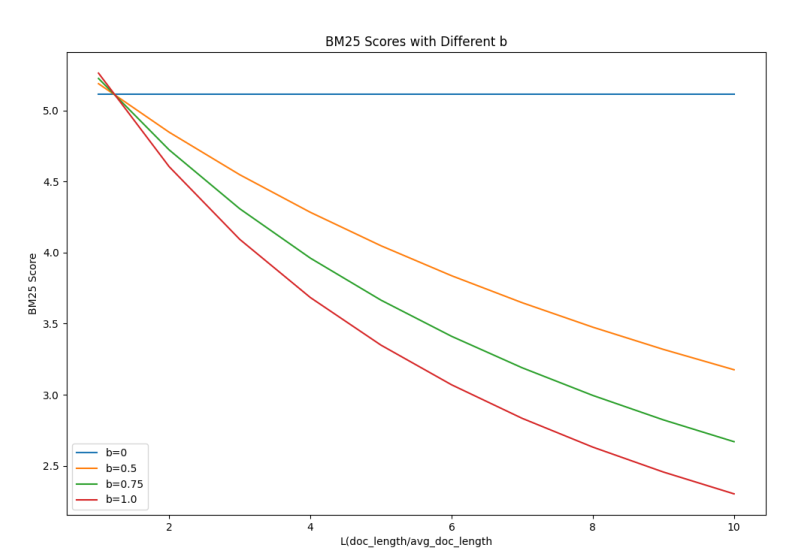
b 参数默认 0.75,主要是对长文档做惩罚。如果设置为 0,分数将与文档的长度无关。从下图可以看到,b=0时,L与分数无关,b=1时,L越大,分数打压越厉害。
完整公式:
$$ \text{BM25}(D, Q) = \sum_{i=1}^{n} \frac{{(k+1) \cdot f_i}}{{f_i + k \cdot (1 - b + b \cdot \frac{{\lvert D \rvert}}{{\text{avgdl}}})}} \cdot \log\left(\frac{{N - n_i + 0.5}}{{n_i + 0.5}}\right) $$单个词项得分
对于查询中的单个词项 $ q_i $,其BM25得分为:
$\text{score}(q_i, D) = \text{IDF}(q_i) \cdot \frac{f_i \cdot (k_1 + 1)}{f_i + k_1 \cdot (1 - b + b \cdot \frac{dl}{avgdl})}$
IDF计算
逆文档频率(IDF)的计算公式为:
$\text{IDF}(q_i) = \log \left( \frac{N - n_i + 0.5}{n_i + 0.5} + 1 \right)$
整体查询得分
对于完整查询 $ Q $,BM25得分为所有词项得分的总和: $\text{BM25}(Q, D) = \sum_{i=1}^{n} \text{score}(q_i, D)$
2.2自己实现
import math
from collections import Counter
class BM25:
def __init__(self, docs, k1=1.5, b=0.75):
"""
BM25算法的构造器
:param docs: 分词后的文档列表,每个文档是一个包含词汇的列表
:param k1: BM25算法中的调节参数k1
:param b: BM25算法中的调节参数b
"""
self.docs = docs
self.k1 = k1
self.b = b
self.doc_len = [len(doc) for doc in docs] # 计算每个文档的长度
self.avgdl = sum(self.doc_len) / len(docs) # 计算所有文档的平均长度
self.doc_freqs = [] # 存储每个文档的词频
self.idf = {} # 存储每个词的逆文档频率
self.initialize()
def initialize(self):
"""
初始化方法,计算所有词的逆文档频率
"""
df = {} # 用于存储每个词在多少不同文档中出现
for doc in self.docs:
# 为每个文档创建一个词频统计
self.doc_freqs.append(Counter(doc))
# 更新df值
for word in set(doc):
df[word] = df.get(word, 0) + 1
# 计算每个词的IDF值(出现的文档数越少,得分越高)
for word, freq in df.items():
self.idf[word] = math.log((len(self.docs) - freq + 0.5) / (freq + 0.5) + 1)
def score(self, doc, query):
"""
计算文档与查询的BM25得分
:param doc: 文档的索引
:param query: 查询词列表
:return: 该文档与查询的相关性得分
"""
score = 0.0
for word in query:
if word in self.doc_freqs[doc]:
freq = self.doc_freqs[doc][word] # 词在文档中的频率
# 应用BM25计算公式
score += (self.idf[word] * freq * (self.k1 + 1)) / (
freq + self.k1 * (1 - self.b + self.b * self.doc_len[doc] / self.avgdl))
return score
if __name__ == "__main__":
# 示例文档集和查询
docs = [["the", "quick", "brown", "fox"],
["the", "lazy", "dog"],
["the", "quick", "dog"],
["the", "quick", "brown", "brown", "fox"]]
query = ["quick", "brown"]
# 初始化BM25模型并计算得分
bm25 = BM25(docs)
scores = [bm25.score(i, query) for i in range(len(docs))]
print(scores)
2.3rank_bm25库
from rank_bm25 import BM25Okapi
import jieba
corpus = [
"BM25是一种常用的信息检索算法",
"这个Python库实现了BM25算法",
"信息检索是搜索引擎的核心技术",
"BM25比传统的TF-IDF效果更好",
"中文信息检索需要先进行分词处理",
"自然语言处理是人工智能的重要领域",
"Python是最受欢迎的编程语言之一",
]
tokenized_corpus = [list(jieba.cut(doc)) for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
def search(query, top_n=3):
tokenized_query = list(jieba.cut(query))
doc_scores = bm25.get_scores(tokenized_query)
top_docs = bm25.get_top_n(tokenized_query, corpus, n=top_n)
return doc_scores, top_docs
query = "Python信息检索"
print(f"查询: '{query}'")
scores, results = search(query)
print("\n相关文档:")
for i, (score, doc) in enumerate(zip(scores, corpus)):
print(f"{i}. [Score: {score:.2f}] {doc}")
print("\n最相关的3个文档:")
for i, doc in enumerate(results):
print(f"{i+1}. {doc}")
2.4bm25s
一个快速的bm25实现方法,在大数据上比其它实现要快,很好用。
项目地址:xhluca/bm25s: Fast lexical search implementing BM25 in Python using Numpy, Numba and Scipy